华为更新“韬定律”:细化了麒麟和昇腾演进路线
时间:2026-07-05 01:31作者:
今年5月25日,华为半导体负责人何庭波在中国科学院科技论文预发布平台ChinaXiv上首次发布《面向多层级电子系统的时间缩微理论》预印本(V1版本),尝试为后摩尔时代的半导体演进寻找一条新的技术路径。
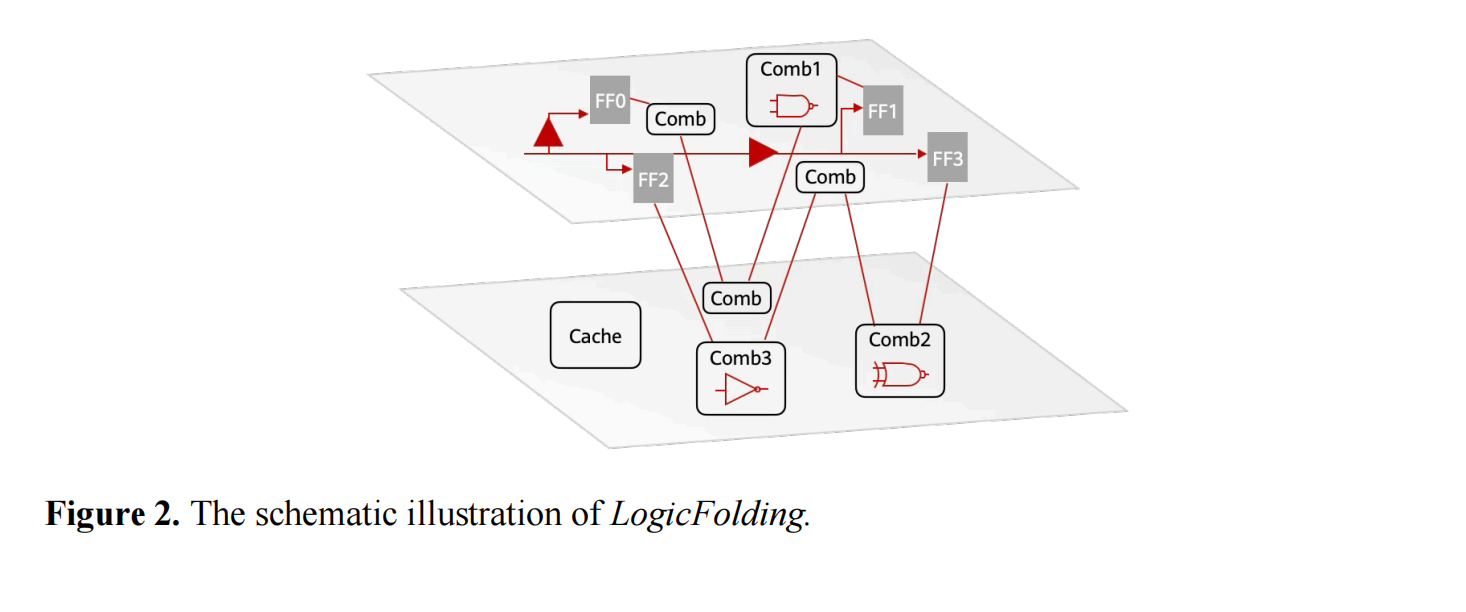
与过去数十年围绕晶体管几何尺寸不断缩小的“几何缩微”不同,这一理论提出,以“时间(τ)缩微”替代“几何缩微”作为电子系统持续演进的新目标,通过LogicFolding(逻辑折叠)、UnifiedBus(统一总线)以及Hi-ONE光互连等技术,从器件、电路、芯片到系统多个层级持续压缩信号传播时间,实现性能、能效与系统集成度的持续提升。
7月3日,何庭波在ChinaXiv发布V2版本。相比V1版本,新版论文的核心理论并未改变,但补充了大量实测数据和工程细节,并进一步细化了麒麟处理器和昇腾AI平台未来数年的演进路线。
对于正触及先进制程物理边界的全球半导体产业而言,这也是此次论文更新最值得关注的变化之一。
用麒麟验证τ定律
相比V1更多回答“什么是τ定律”,V2版本用更多数据进一步解释这套理论如何落地。
以论文核心提出的三维逻辑折叠为例,V1主要介绍了利用三维堆叠缩短关键路径、降低RC延迟、提升频率和晶体管密度的基本思路,而V2进一步阐释了这一技术能够实现的关键工程条件。
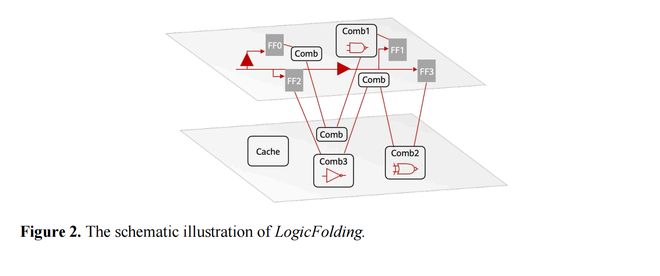
论文中新增了“GearRatio(齿轮比)”概念,用于描述HybridBonding(混合键合)间距与顶部金属层布线间距之间的关系。论文指出,只有当垂直互连间距与顶部金属层间距足够接近(齿轮比低于3,理想趋近于1)时,设计空间才能从传统的宏块级离散优化(DiscreteOptimization)转变为单元级连续优化(ContinuousOptimization)。
这一转变至关重要,它使得EDA工具能够将多个主动层视为一个连续的整体、以标准单元粒度进行跨层协同设计,而不再受限于按功能模块强行分层的粗放式做法,从而释放三维堆叠的真正潜力。论文还指出,为实现这一目标,华为在超细间距混合键合、TSV微缩及叠层精度控制方面经历了多年的工艺开发努力。
在V1中,华为已经列出了逻辑折叠驱动下麒麟处理器未来数代的发展规划,而V2在此基础上新增了晶体管密度与CPU频率的投影曲线图,将CPU性能核心频率、晶体管密度以及逻辑折叠演进纳入更加完整的量化框架。在移动端,V2明确补充了TSV从顶层金属逐步下移至M6层(可释放超过30%的高层布线资源)、以及从两层向三层、四层多有源层堆叠的演进路径。时间上,华为昇腾Ascend990将在2030年前后引入逻辑折叠。
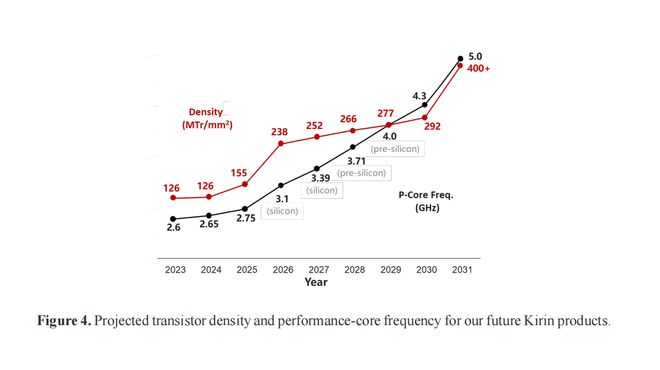
相比路线图本身,更大的变化来自论文新增的大量工程验证数据。V2版本中新增了Kirin2026与Kirin9030Pro在等性能条件下的实测对比,展示两款芯片在相同性能目标下的电压、功耗及功率密度变化。数据显示,在25℃环境、等性能目标下,Kirin2026可将供电电压由1.1V降低至0.9V,归一化功耗下降至0.59(即功耗降低41%),同时归一化功率密度下降约5.6%。
在业内看来,相比V1主要展示性能结果,V2补充了实现这些结果背后的工程约束、热管理策略与设计方法论,进一步推动τ定律从理论框架逐渐演变为一套可以持续验证的芯片设计方法。
从芯片到AI集群
除了移动终端之外,V2版本另一项值得关注的变化,是更加完整地解释了τ定律如何从单颗芯片扩展到整个AI计算系统。
华为认为,随着大模型持续演进,AI系统面临的瓶颈已经不再只是单颗芯片的计算能力,而是计算、互连、存储、供电等多个层级的发展速度逐渐失衡。未来AI基础设施若要继续提升性能,需要从系统层面持续压缩时间常数τ,而不仅依赖单一制程节点的演进。

在具体实现路径上,更新后的论文通过新增的多张示意图进一步阐述了UnifiedBus、Hi-ONE以及3DFolding三项技术在系统中的分工与协同,三项技术共同作用于不同层级的τ优化,形成从芯片、互连到AI集群的系统级协同设计。
此外,在V1版本中,华为还明确提出了包括适配三维逻辑划分的EDA工具链、晶圆间工艺偏差补偿、垂直互连开销、系统能耗以及新型基准测试方法等一系列待解决的关键问题。同时在V2中补充了热感知设计策略及其对应的功率密度实测数据。