OpenAI GPT-4o推出图像生成功能,攻克“生成图像中的文字”难题
时间:2025-03-27 00:00作者:
图像生成领域传来了新进展,OpenAI在攻克“生成图像中的文字”方面的难题。北京时间3月26日凌晨,OpenAI进行了直播,对GTP-4o和Sora进行更新,在ChatGPT和Sora中推出GPT-4o的图像生成功能。OpenAI此次强调了新功能在精准理解文本描述、准确生成文本方面的优势。
据OpenAI介绍,GPT-4o图像生成功能擅长准确呈现文本,并精准遵循提示词,该功能还会将GPT-4o的知识库和聊天上下文作为灵感来源,这有助于使用者与图像生成工具更有效地沟通并提高生成图像的质量。该功能供ChatGPTPlus、Pro、Team和免费用户使用,并计划随后向企业、教育和API使用者推出。
在OpenAI的示例中,要求大模型生成一名女子在一个俯瞰海湾大桥的房间里用笔在白板上写字,衣服上印有OpenAI字样,白板映着摄影师的身影,并描述了白板上所写的文字。GPT-4o生成的图像都体现了以上要求。随后,OpenAI要求摄影师走到镜头前与女子击掌,GPT-4o也呈现了这一画面,且白板上的字不会变得凌乱,女子的身形和发型也与前一张图像呈现的背影一致。

在其他示例中,OpenAI要求大模型生成上世纪中叶一个家庭中冰箱上贴着的诗歌短句,并要求画面中的人手拿着特定的几个词,GPT-4o可以精准还原。GPT-4o还能生成漫画,但需要人准确地描述画面中的情节。OpenAI还展示了这个图像生成功能在科学实验中的用途,该功能可以生成牛顿棱镜实验的示意图。此外,OpenAI还展示了该图像生成功能在生成路牌、菜单、游戏画面时的效果,以及生成鸡尾酒配方、天气信息图像时,大模型生成的专业配方和天气文本描述。

就如何训练GPT-4o图像生成功能,OpenAI解释,OpenAI使用了网络上的图像和文本训练模型,让模型学习图像与文字、图像与图像之间的关系,使模型具有视觉流畅性,生成的图片是有用的、具备上下文连贯性的。
就GPT-4o图像生成功能的特点,OpenAI还表示,用户可以通过自然对话与大模型交流,要求大模型改进图像,在这个过程中图像中的人物等要素会保持一致性。使用者与大模型的交流也更顺畅,可以同时要求大模型处理10到20个不同的对象,以便图像中各要素呈现出相关性。OpenAI对比其他图像生成系统时称,其他系统只能同时处理5到8个对象。
不过,OpenAI也指出,GPT-4o图像生成功能也具备一些限制,例如存在幻觉、难以呈现太多依赖知识库的图像要素(例如元素周期表)、图表准确性不足、呈现非拉丁语言时可能容易出现幻觉、要求修改图像中的错别字时难以精准编辑。
生成图像中的文字,此前是图像生成领域的一个难题。国内,去年豆包升级文生图能力,支持一键生成指定文本。今年3月,智谱AI发布了首个支持生成汉字的开源文生图模型CogView4。不过,记者试用发现,相关模型生成文字的能力还不太稳定。
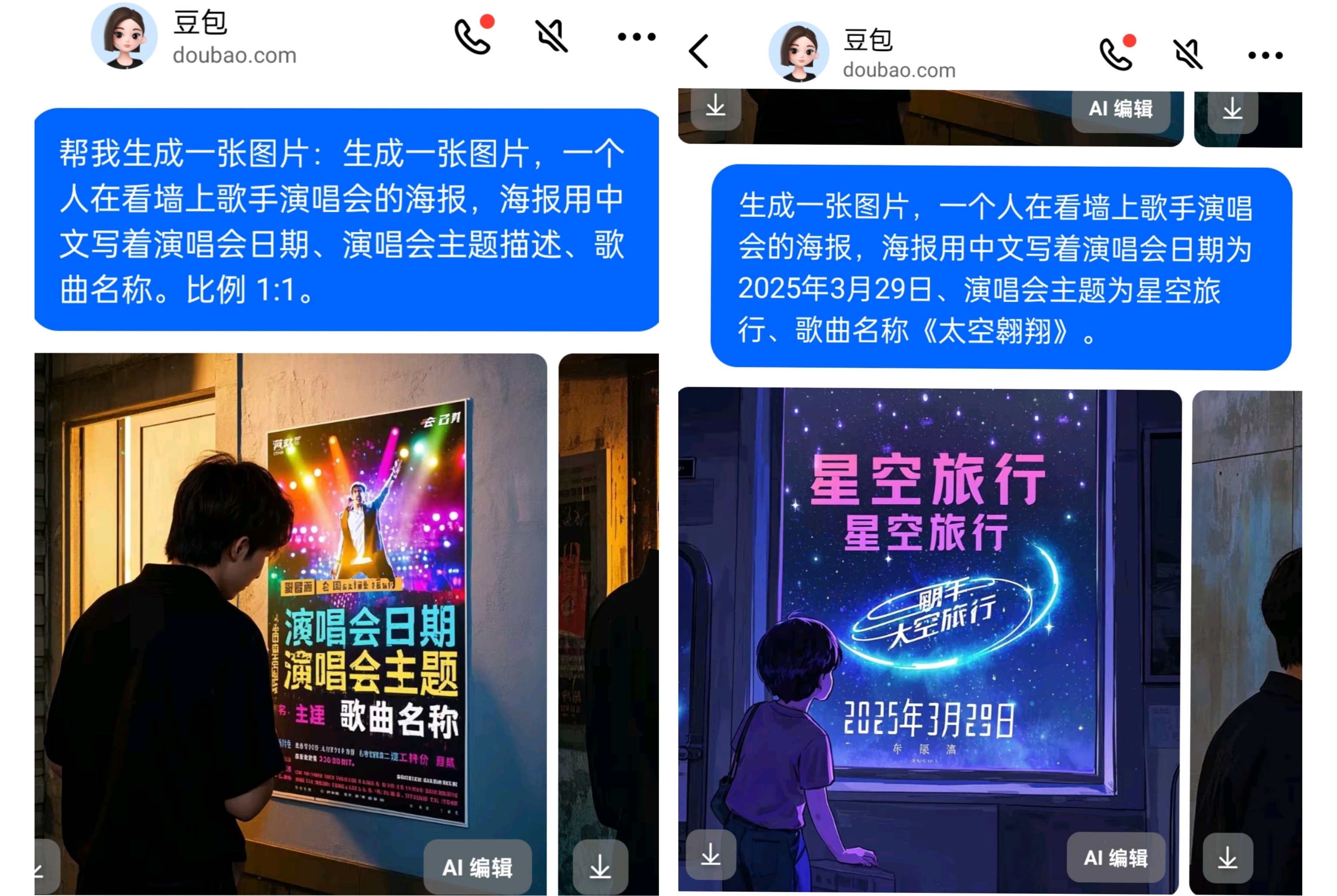
3月26日,记者使用豆包APP和智谱清言APP生成图像,其中智谱清言用的模型是CogView4。记者输入“生成一张图片,一个人在看墙上歌手演唱会的海报,海报用中文写着演唱会日期、演唱会主题描述、歌曲名称”。智谱清言生成的海报中出现不少乱码。豆包生成的中文文字准确,但理解有所偏差,呈现的是“演唱会日期”“演唱会主题”这些字样。
随后记者将提示词改为“一个人在看墙上歌手演唱会的海报,海报用中文写着演唱会日期为2025年3月29日、演唱会主题为星空旅行、歌曲名称《太空翱翔》”,豆包呈现出了正确的日期和“星空旅行”字样,仍有一些字是乱码,智谱清言也生成了一些乱码。

更新GPT-4o的图像生成功能之后,OpenAI更大的产品更新将是推出GPT-5。今年2月,OpenAI首席执行官山姆·奥尔特曼表示,OpenAI将会在ChatGPT和API服务中搭载新模型GPT-5,GPT-5将集成公司多项技术,包括推理模型o3的技术,GPT-5可能会在未来几个月内推出。






