一夜之间,微软、英伟达、亚马逊全部接入DeepSeek!吴恩达:中国AI正在崛起
时间:2025-02-01 02:00作者:
新智元报道
[新智元导读]微软、英伟达、亚马逊等美国云计算平台拥抱DeepSeekR1。吴恩达、英特尔前CEO夸赞DeepSeek创新能力。
1月最后一天,来自DeepSeek的热度丝毫不减。
远在大洋彼岸的美国,不仅从业者感受到了前所未有的压力,那些平时对AI毫不关心的人,也感受到了来自中国AI的震撼——
AnthropicCEO呼吁美国加强芯片管制力度;OpenAI寻求硅谷史上最大400亿美元单笔融资。
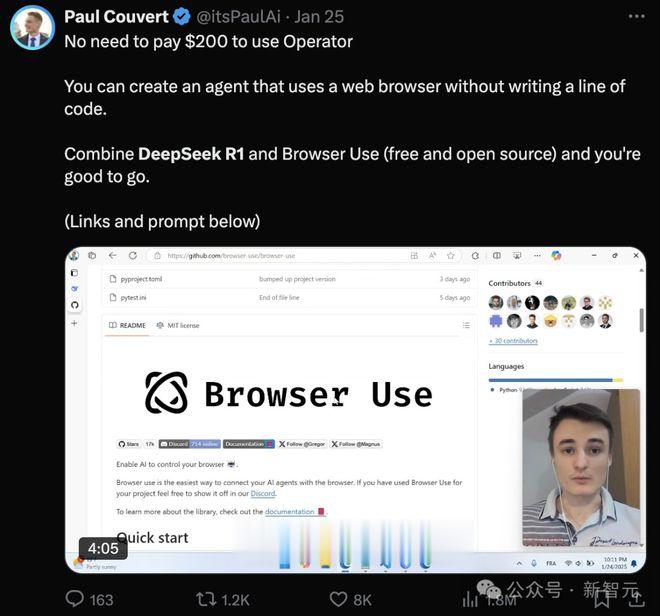
网友们则借助宽松的开源许可,制作出了用DeepSeek-R1替代OpenAIOperator的教程——不用200美元订阅,完全免费!
‘俗话’说得好:‘打不过就加入’。
一开始便对DeepSeek赞赏有加的英伟达,刚刚宣布:‘DeepSeek-R1正式登陆NVIDIANIM’。据介绍,在单个NVIDIAHGXH200系统上,完整版DeepSeek-R1671B的处理速度可达3,872Token/秒。
同在今天,亚马逊也在AmazonBedrock和SageMakerAI中,上线了DeepSeek-R1模型。

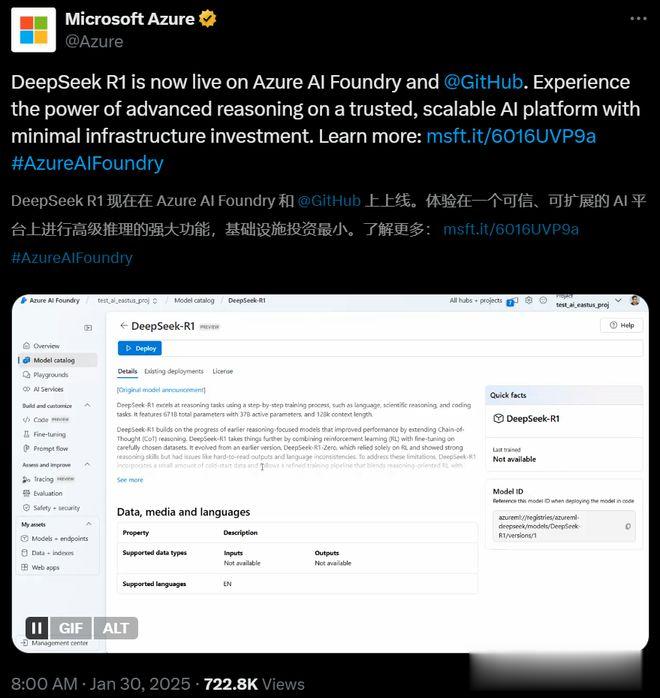
曾经冲出来和OpenAI一起高调质疑DeepSeek‘偷窃’数据的微软,甚至在前一天就把DeepSeek-R1抢先部署在了自家的云服务Azure上。
除了科技大厂,AI初创们也没有放过如此上好的机会。
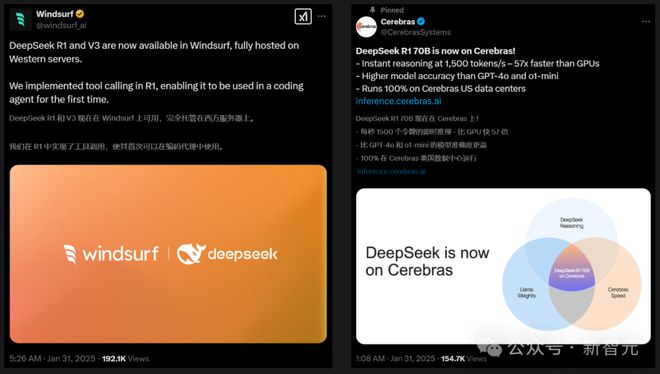
Windsurf编辑器同时集成了DeepSeek-R1和V3模型,并且第一次在编程智能体中,实现了R1的工具调用。
Cerebras不仅实现了比GPU快57倍的推理速度,而且还报告称,自己部署的70B模型在准确率上要比GPT-4o和o1-mini更高。
中国AI正在崛起
在吴恩达看来,本周围绕DeepSeek的热议,让许多人清晰地看到了几个一直存在的重要趋势:

中国在GenAI领域正在赶上美国
当ChatGPT于2022年11月推出时,美国在GenAI领域明显领先于中国。
由于观念的转变十分缓慢,所以吴恩达直到最近,都还能听到不少关于中国仍然落后的论调。
但实际上,双方的差距已经在过去两年中迅速缩小。
随着Qwen(吴恩达团队已经用了几个月)、Kimi、InternVL和DeepSeek等模型的推出,中国在文本模型上的差距正在缩小,而在视频生成等领域,中国甚至已经展现出了一些领先优势。
如今,DeepSeek-R1不仅开源了模型权重,而且还分享了一份包含诸多细节的技术报告。
相比之下,一些美国公司却通过渲染人类灭绝等假想的AI危险,推动制定法规来阻止开源的发展。
不可否认的是,开源/开放权重模型都是AI供应链的关键部分——很多公司都在用。
对此,吴恩达表示:如果美国继续妨碍开源,AI供应链的这一环节就将由中国主导。
开放权重模型正在使基础模型层普及化
一直以来,LLM的Token价格都在迅速下降,开放权重模型不仅加速了这一趋势,并且还为开发者提供了更多选择。
OpenAI的输出价格为60美元/百万Token;而DeepSeekR1只要2.19美元。这种近30倍的差异让许多人注意到了价格下降的趋势。
训练基础模型并提供API服务充满困难,很多AI公司至今仍在寻找收回模型训练成本的途径。
红杉资本的文章‘AI’s$600BQuestion’很好地阐述了这一挑战。
相比之下,在基础模型之上进行应用开发,则有着绝佳的商机。
现在,已经有公司投入了数十亿美元训练出了一些模型,而你只需支付少量费用就能访问。然后,拿去开发客服聊天机器人、邮件摘要工具、AI医生、法律文档助手等诸多应用。

扩大规模并非AI进步的唯一途径
围绕通过扩大模型规模来推动进步的热议有很多,就连吴恩达也是早期的支持者之一。
许多公司为了数十亿美元的融资,制造‘噱头’:
因此,人们开始过分关注规模的scaling,而忽视了其他方式取得的进步。
受到美国AI芯片禁令的影响,DeepSeek团队不得不在性能相对较低的H800GPU上跑模型,而这也推动了他们在优化方面的大量创新。最终,模型训练成本(不包括研究成本)不到600万美元。
这是否真能减少计算需求仍有待观察。有时,商品的单价变得更低,反而会导致该商品的总支出增加。
吴恩达认为:‘从长远来看,对智能和算力的需求是几乎没有上限的,所以即使智能变得更便宜,人类依然会使用更多智能。’

在X上,我们可以看到很多对DeepSeek进展的不同解读。就像‘罗夏墨迹测试’一样,可以让许多人将自己的理解投射其中。
虽然DeepSeek-R1的地缘政治影响仍有待明确,但它对AI应用的开发者来说确实是个好消息。
吴恩达的团队已经在头脑风暴一些新的想法,而这些想法之所以成为可能,仅仅是因为我们可以轻松访问一个开放的高级推理模型。
现在仍然是一个创造的好时机!
DeepSeek带来的三个启示
DeepSeek的成功,甚至‘炸出’了芯片、计算行业的老兵——英特尔前CEOPatGelsinger。
作为业内非常资深的工程师,Gelsinger认为,现在这些针对DeepSeek的反应,忽视了我们在过去五十年计算机发展历程中学到的三个重要教训。
第一:计算遵循‘气体定律’
计算会像气体一样,填满由可用资源(资本、电力、散热限制等)定义的可用空间。
正如在CMOS、个人电脑、多核处理器、虚拟化、移动设备等众多领域看到的那样,以极低的价格广泛提供计算资源,将推动市场的爆炸性扩张,而不是收缩。
未来AI将无处不在,而今天,要实现这一潜力的成本仍然高得离谱。
第二:工程的本质就是应对约束
很明显,DeepSeek团队面临诸多约束,但他们找到了极具创造性的方法,并以低10-50倍的成本,交付了世界一流的解决方案。
美国的禁令限制了可用资源,因此中国的工程师不得不发挥创造力,而他们也确实做到了——价值数百亿美元的硬件、最新的芯片和数十亿美元的训练预算,都不再是必需品。
多年前,Gelsinger曾采访过最为著名的计算机科学家之一DonaldKnuth。他详细描述了当资源极度受限、进度要求最紧迫时,该如何做出最好的工作。
Gelsinger表示,这个见解是他工程管理生涯中最重要的启示之一。
第三:开放终将胜利
过去几年,看到正变得越来越封闭的基础模型研究,实在令人失望。
在这一点上,Gelsinger更认同马斯克而不是奥特曼的观点——我们真的希望,不,是需要AI研究的开放性得到提升。
我们需要知道训练数据集是什么,研究算法并对其正确性、伦理和影响进行深入思考。Linux、GCC、USB、WiFi等众多例子,已经让这一点无比清晰。
在法律、频谱、工程和采用方面的战斗中,开放并不容易,并且始终在受到市场力量的挑战。但只要给一个适当的机会,‘开放’每次都会胜出。
AI对人类未来的重要性不言而喻,因此,绝对不能让一个封闭的生态系统在这个领域成为唯一的主宰。
DeepSeek是一个令人难以置信的工程壮举——它将推动AI实现更广泛发采用,并将帮助重塑行业对开放创新的看法。
正是这样一个来自中国的高度受限的团队,让我们所有人重新想起了这些计算机历史的基本教训。